DISCount: Counting in Large Image Collections with Detector-based Importance Sampling
Many modern applications use computer vision to detect and count objects in massive image collections. For example, we are interested in applications that involve counting bird roosts in radar images and damaged buildings in satellite images. The image collections are too massive for humans to solve these tasks in the available time. Therefore, a common approach is to train a computer vision detection model and run it exhaustively on the images.
The task is interesting because the goal is not to generalize, but to achieve the scientific counting goal with sufficient accuracy for a fixed image collection. The best use of human effort is unclear: it could be used for model development, labeling training data, or even directly solving the counting task!
A particular challenge occurs when the detection task is very difficult, so the accuracy of counts made on the entire collection is questionable even with huge investments in training data and model development.
Some works resort to human screening of the detector outputs, which saves time compared to manual counting but is still very labor intensive.
These considerations motivate statistical approaches to counting. Instead of screening the detector outputs for all images, a human can "spot-check" some images to estimate accuracy, and, more importantly, use statistical techniques to obtain unbiased estimates of counts across unscreened images. In a related context, Meng et al. proposed IS-count, which uses importance sampling to estimate total counts across a collection when (satellite) images are expensive to obtain by using spatial covariates to sample a subset of images.
We contribute counting methods for large image collections that build on IS-count in several ways. First, we work in a different model where images are freely available and it is possible to train a detector to run on all images, but the detector is not reliable enough for the final counting task, or its reliability is unknown. We contribute human-in-the-loop methods for count estimation using the detector to construct a proposal distribution, as seen in Fig. 2. Second, we consider solving multiple counting problems---for example, over disjoint or overlapping spatial or temporal regions---simultaneously, which is very common in practice. We contribute a novel sampling approach to obtain simultaneous estimates, prove their (conditional) unbiasedness, and show that the approach allocates samples to regions in a way that approximates the optimal allocation for minimizing variance. Third, we design confidence intervals, which are important practically to know how much human effort is needed. Fourth, we use variance reduction techniques based on control variates.
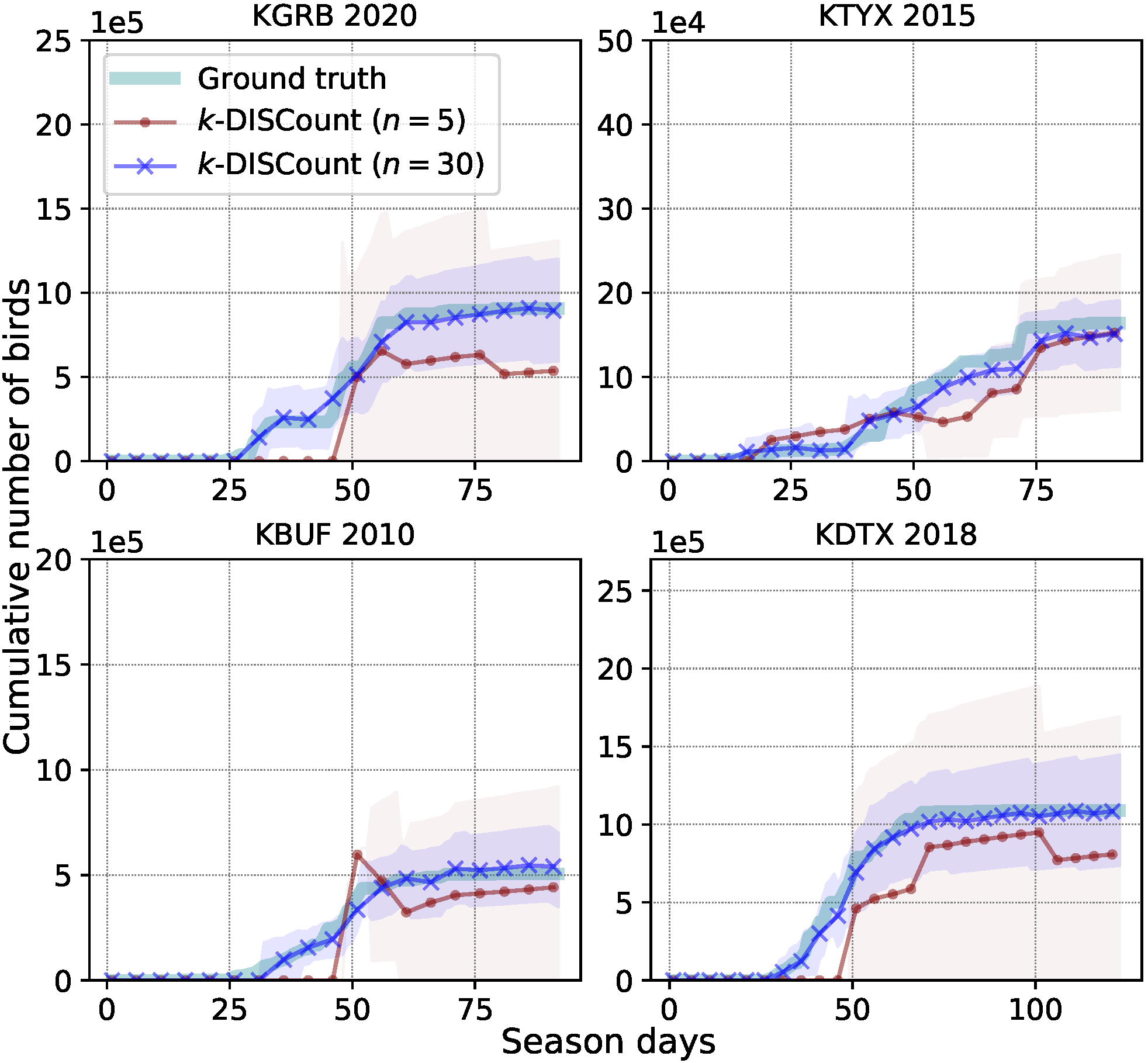
Fig. 1 Count estimates with confidence intervals for two station years (i.e., KGRB 2020 and KBUF 2010) using different numbers of samples.
Our method produces unbiased estimates and confidence intervals with reduced error compared to covariate-based methods. In addition, the labeling effort is further reduced with DISCount as we only have to verify detector predictions instead of producing annotations from scratch. On our tasks, DISCount leads to a 9-12x reduction in the labeling costs over naive screening and 6-8x reduction over IS-Count. Finally, we show that solving multiple counting problems jointly can be done more efficiently than solving them separately, demonstrating a more efficient use of samples.

Fig. 2 k-DISCount uses detector-based importance sampling to screen counts and solve multiple counting problems. (left) Geographical regions where we want to estimate counts of damaged buildings. (middle-left) Outputs of a damaged building detector on satellite imagery, which can be used to estimate counts g(s) for each tile (shows as dots). (middle) Tiles selected for human screening to obtain true counts f(s), from which counts for all regions are joinly estimated by k-DISCount. (right) Our experiments show that DISCount outperforms naive (MC) and covariate-based sampling (IS-Count)
The problem
Counting roosting birds in radar data
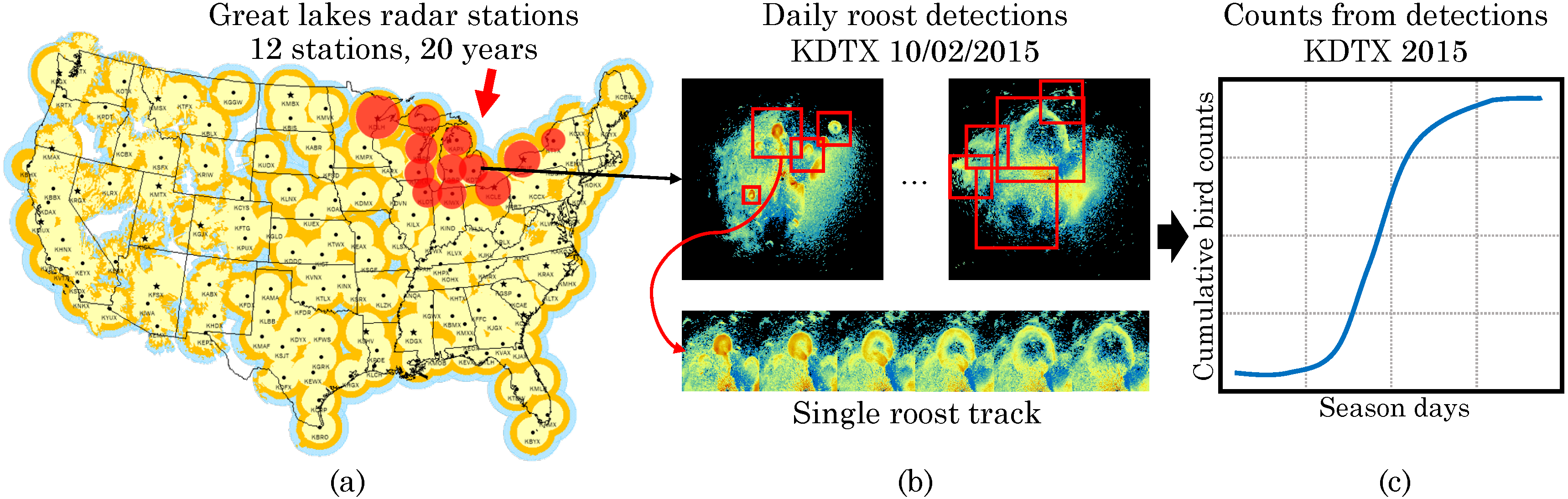
Fig. 3 Counting roosting birds in radar images. (a) The US weather radar network has collected data for 30 years from 143+ stations and provides an unprecedented opportunity to study long-term and wide-scale biological phenomenon such as roosts. (b) Counts are collected for each day s by running the detector using all radar scans for that day to detect and track roost signatures and then mapping to bird counts using the radar "reflectivity" within the tracks. The figure shows two scans for the KDTX station (Detroit, MI) on the same day, along roost detections which appear as expanding rings. By tracking these detections across a day one can estimate the number of birds in each roost. (c) Cumulative bird counts in the complete roosting season by aggregating counts across all tracked roosts and days.
Counting damaged buildings from satellite images

Fig. 4 Counting damaged buildings in satellite images. Building damage assessment from satellite images is often used to plan humanitarian response after a natural disaster strikes. (a) We consider the Palu Tsunami from 2018; the data consists of 113 high-resolution satellite images labeled with 31,394 buildings and their damage levels. (b) Counts are collected per tile using before- and after-disaster satellite images. Colors indicate different levels of damage (e.g., red: "destroyed"). (c) Damaged building counts per sub-region.
The method
DISCount: detector-based importance sampling
IS-count assumes images are costly to obtain, which motivates using external covariates for the proposal distribution.
However, in many scientific tasks, the images are readily available, and the key cost is that of human supervision.
In this case it is possible to train a detection model and run it on all images to produce an approximate count g(s) for each s.
We propose the detector-based IS-count ("DISCount") estimator, which uses the proposal distribution proportional to g on region S.
The importance-sampling estimator then specializes to:
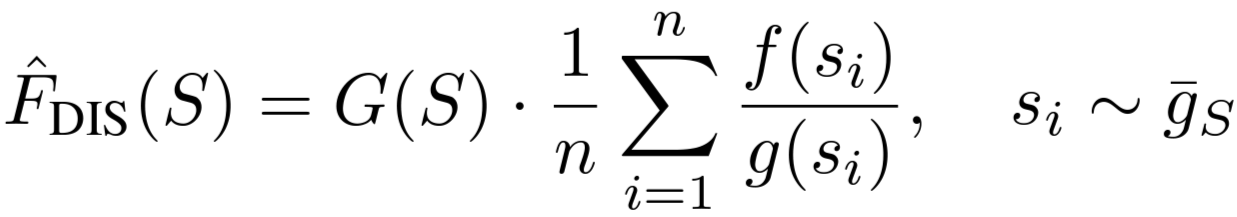
k-DISCount
We now return to the multiple region counting problem. A naive approach would be to run DISCount separately for each region.
However, this is suboptimal.
First, it allocates samples equally to each region, regardless of their size or predicted count.
Intuitively, we want to allocate more effort to regions with higher predicted counts.
Second, if regions overlap it is wasteful to repeatedly draw samples from each one to solve the estimation problems separately.
We propose estimators based on n samples drawn from all of Ω with probability proportional to g.
Then, we can estimate F(S) for any region using only the samples from S. Specifically, the k-DISCount estimator is
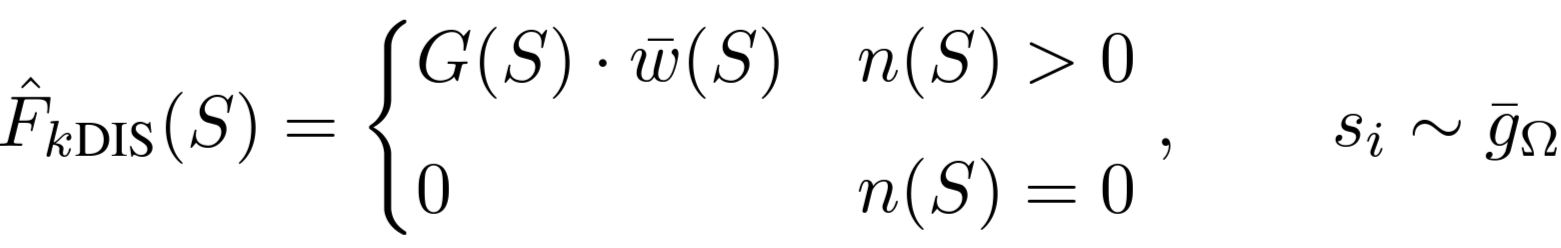
Results
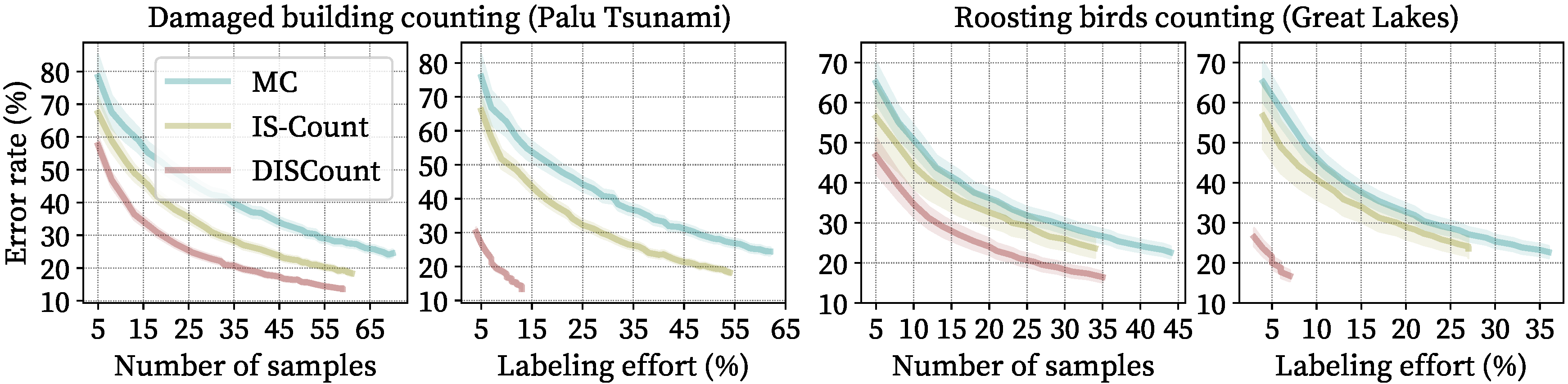
Fig. 5 Detector-based sampling. Estimation error of damaged building counts in the Palu Tsunami region from the xBD dataset (left) and counting roosting birds from the Great Lakes radar stations in the US from NEXRAD data (right). We get lower error with DISCount compared to IS-Count and simple Monte Carlo sampling (MC). The labeling effort is further reduced with DISCount since the user is not required to label an image from scratch but only to verify outputs from the detector. The estimation errors are averaged over 1000 runs.
Publications
DISCount: Counting in Large Image Collections with Detector-Based Importance Sampling
Gustavo Perez, Subhransu Maji*, Daniel Sheldon* (*equal advising)
arXiv, 2023.
preprint ·
BibTex
|