Star Cluster Classification from Nearby Galaxies
The Hubble Space Telescope (HST), the recently launched James Web Space Telescope (JWST), and many earth-based observatories collect data allowing astronomers to answer fundamental questions about the Universe. In this work we focus on an ecosystem of AI tools for cataloging bright sources within galaxies, and use them to analyze young star clusters -- groups of stars held together by their gravitational fields. Their ages and masses, among other properties provide insights into the process of star formation and the birth and evolution of galaxies. Significant domain expertise and resources are required to discriminate star clusters among tens of thousands of sources that may be extracted for each galaxy. To accelerate this step we propose: 1) a web-based annotation tool to label and visualize high-resolution astronomy data, encouraging efficient labeling and consensus building; and 2) techniques to reduce the annotation cost by leveraging recent advances in unsupervised representation learning on images.
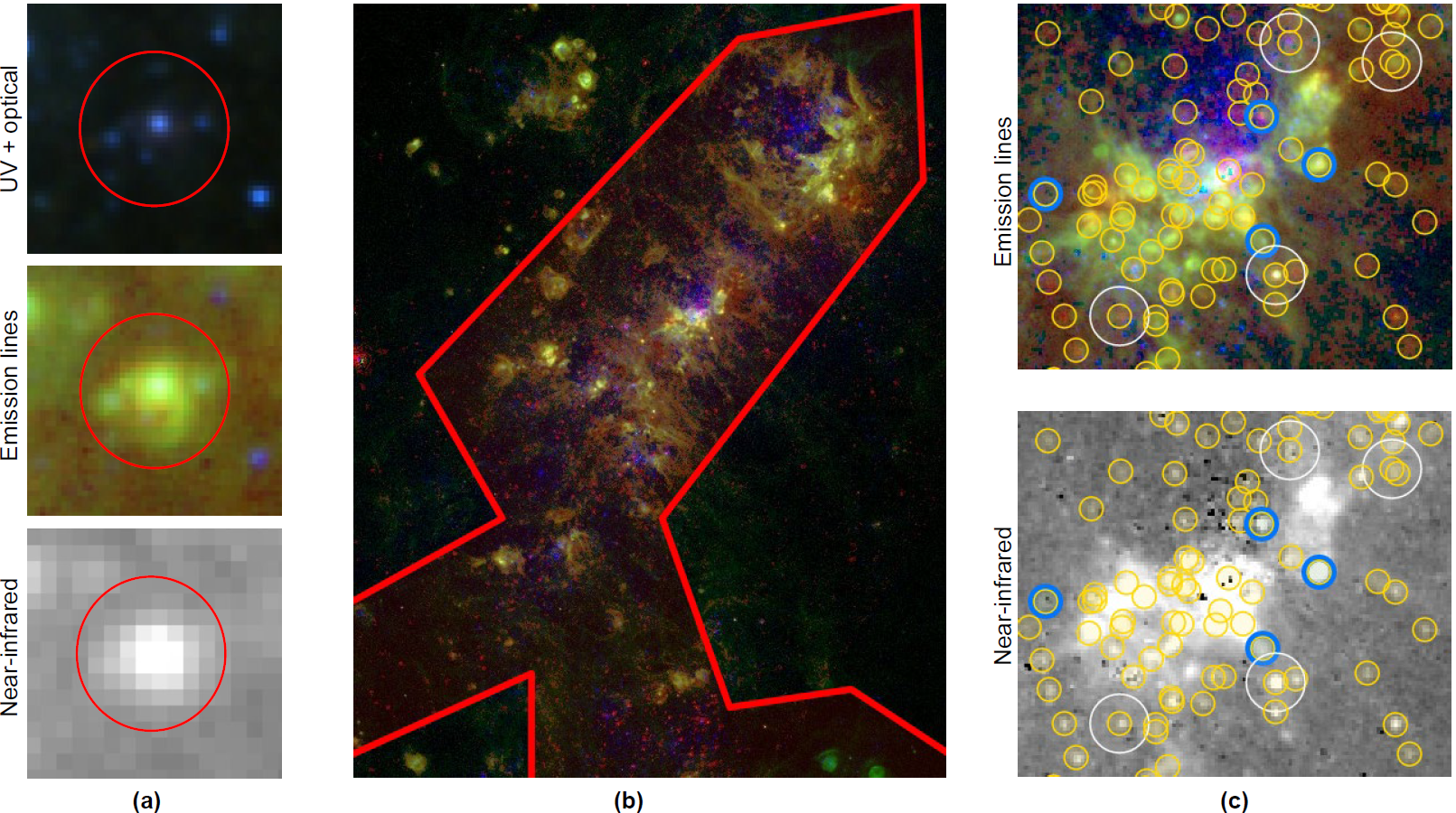
Fig. 1 (a) Example of a young cluster inside an HII region. The cluster is shown in UV + optical bands (top), Emission lines (middle), and low-resolution near-IR (bottom). (b) Region with high HII concentration to sample sources for annotation. (c) Crops of our labeling tool showing SExtractor sources (yellow circle markers), sources also in the final LEGUS catalog for NGC 4449 (blue circle marker), and sources sampled for annotation (white large circle marker).
Publications

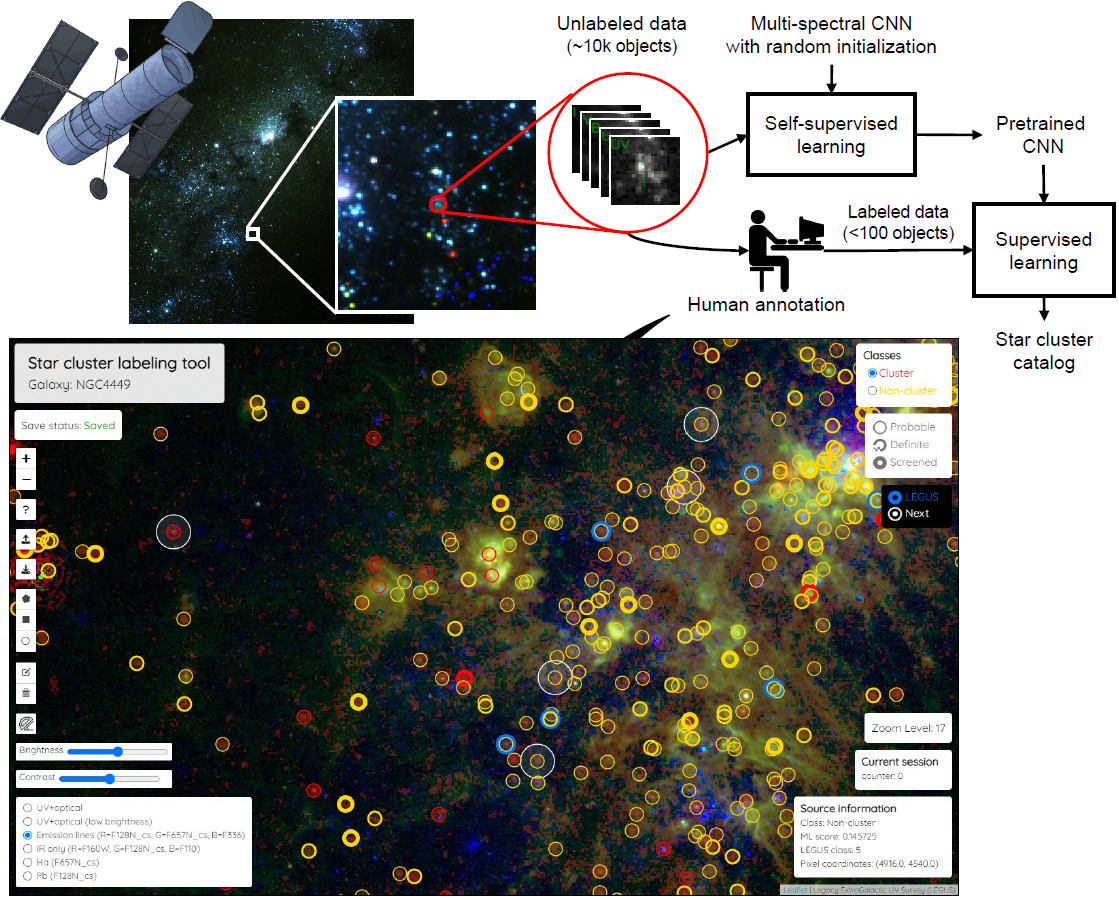
Fig. 4. The proposed tool for cataloging sources within galaxies. (Top) An AI model assists data labeling by using the few labels provided initially to guide further labeling. (Bottom) A web-based user interface to label sources. The UI allows annotators to zoom into different regions dynamically and can be customized to support different labels (e.g., center coordinates, bounding boxes, irregular polygons) and spectral measurements as layers. In this figure we show a customized version of the UI for IR images showing annotations overlaid on HST observations of galaxy NGC 4449.
Annotation tool demo
Cite this paper

Github code repository
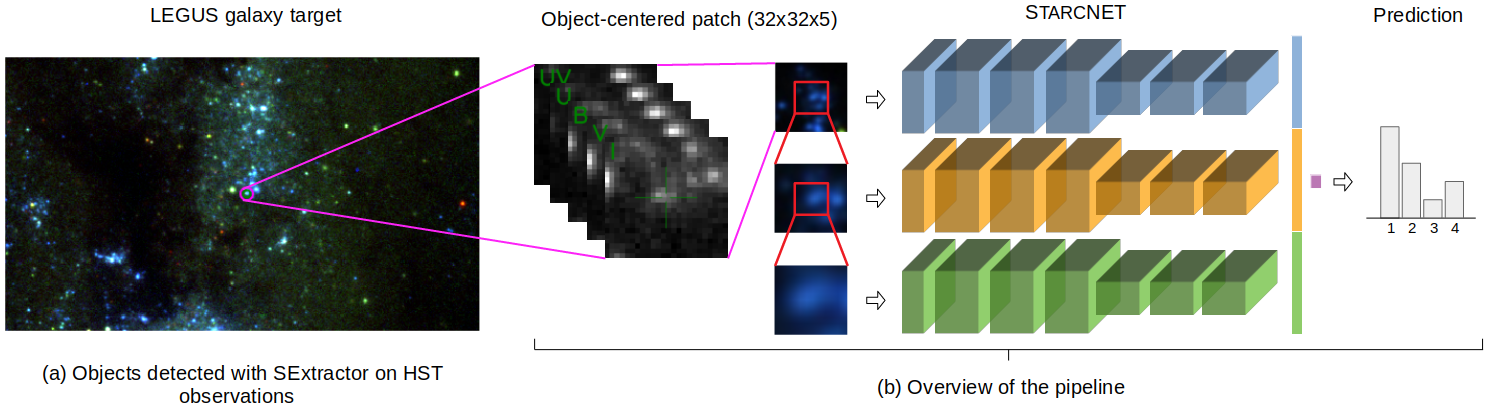
Fig. 2 The StarcNet pipeline. Graphic sketch of the machine learning pipeline used in this work to classify cluster candidates in the LEGUS images. (Left): The Hubble Space Telescope images as processed by the LEGUS project through a custom pipeline to generate automatic catalogs of cluster candidates, which are part of the public LEGUS catalogs release (Calzetti et al. 2015; Adamo et al. 2017); we apply StarcNet to the LEGUS catalogs and images. (Center–Left): The region surrounding each candidate is selected from the 5 band images at three magnifications, and is used as input to our multi-scale StarcNet. (Center–Right and Right): Each of the three pathways of the CNN consists of 7 convolutional layers, which are later connected to produce a prediction for the candidate in one of four classes.
We developed StarcNet, a multiscale CNN, with the goal of morphologically classifying stellar clusters in nearby galaxies. StarcNet aims at speeding up by orders of magnitude the process of visual cluster classification, which currently is the single most important limitation to securing large catalogs for studies of these sources. Availability of reliable and fast ways to classify star clusters will become even more critical with the advent of extremely large surveys, such as those that will be produced by the Vera Rubin Observatory and the Nancy Roman Space Telescope.
NSF Award #1815267
Cite this paper

