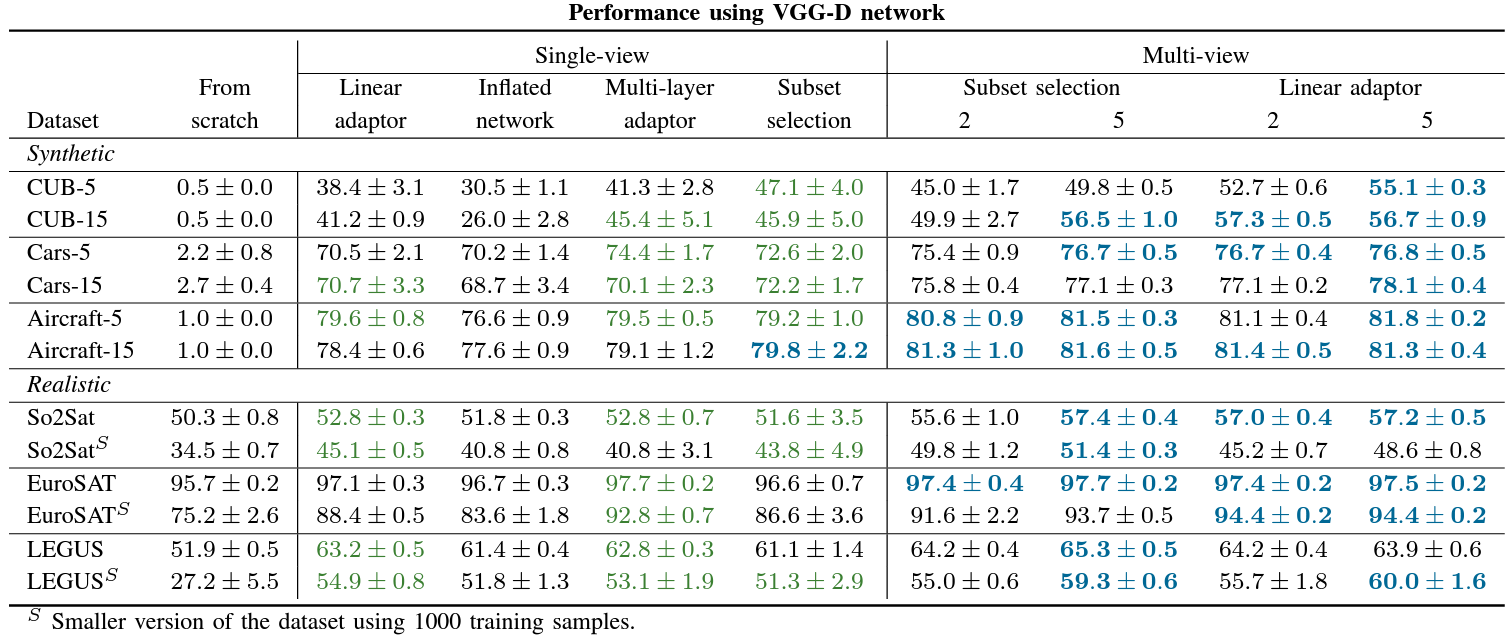
Domain Adaptors for Hyperspectral Images
Gustavo Perez, Subhransu Maji
Github code repository
Transferring deep networks trained on large datasets of color images has been a key to their success on visual recognition. However, the effectiveness of the transfer depends in part on how related the source and target domains are. For example, models trained on Internet images may not be as effective on recognizing medical or astronomy images. A further challenge arises when transferring to heterogeneous domains where some architectural modification to the network is necessary for it to process the input. This paper studies this problem by designing a domain adaptor network that can be plugged in before a color image network to process hyperspectral images consisting of different number of channels. These schemes are illustrated in Fig. 1.
Our problem is motivated by the fact that hyperspectral domains lack pretrained networks that can serve as general-purpose feature extractors. Thus one might benefit from architectural innovations and datasets in the domain of color images which are readily available in "model zoos" in modern libraries. While the literature contains several schemes for transferring pretrained networks from color to hyperspectral domains, a systematic evaluation is lacking. Our first contribution is therefore a benchmark of six hyperspectral datasets divided into two groups. The first contains three remote sensing datasets: LEGUS, So2Sat LCZ42, and EuroSAT. The second modifies the images in Caltech-UCSD birds, FGVC aircraft, and Stanford cars datasets by synthetically expanding the channels. The synthetic datasets allow us to measure the effectiveness of transfer by comparing it with the performance on the unmodified color images and control the amount of domain shift by varying the number of channels. Despite their simplicity these datasets reveal some difficulties in transfer learning. For example, permuting the color channels makes the transfer significantly less effective on the CUB dataset. We analyze this phenomenon and it's implications.
Our second contribution is an evaluation of common schemes in the literature. These include: (a) a linear projection; (b) selecting a subset; (c) a multi-layer network; (d) "inflating" the first layer of the network. We also investigate techniques for pre-training adaptors in an unsupervised manner. Finally, we propose a novel multi-view scheme that generates a prediction by aggregating information across "views" of the input as illustrated in Fig. 1.
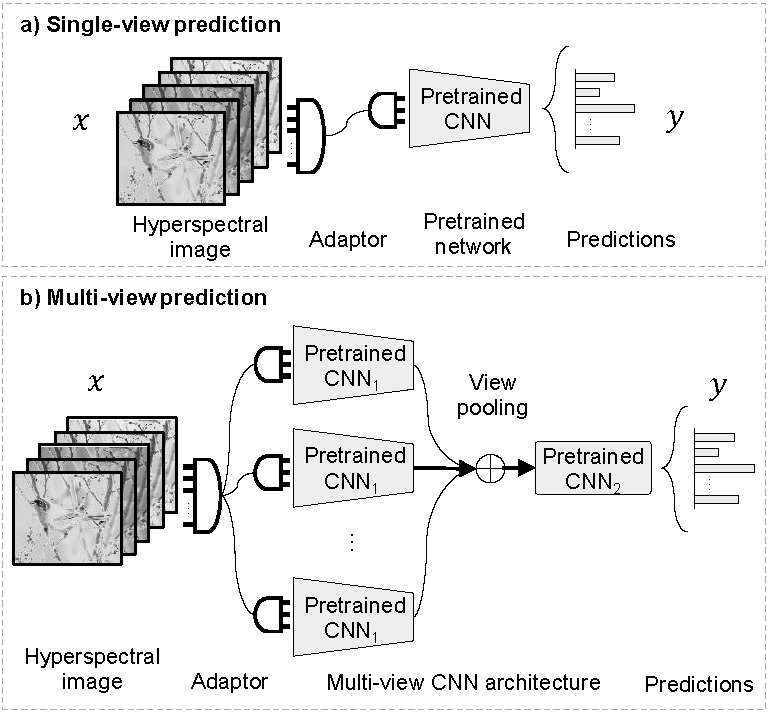
Fig. 1 Single and multi-view adaptors. (a) An adaptor maps multiple channels to three, making it compatible with a pretrained color network. (b) Multiple adaptors generate views of the input which are processed through a shared network.